<figure class="wp-block-image"><img src="https://labdx.org/wp-content/uploads/2026/05/what-is-artificial-intelligence-1024x682-1.jpg?wsr" alt="O atributo alt desta imagem está vazio. O nome do arquivo é what-is-artificial-intelligence-1024x682-1.jpg"/></figure>
<h1 class="wp-block-heading">Inteligência artificial (IA)</h1>
<p class="wp-block-paragraph">A inteligência artificial (IA) abrange muitas tecnologias complexas e emergentes que antes exigiam intervenção humana e agora podem ser realizadas por um computador. </p>
<p class="wp-block-paragraph">De modo geral, a IA é um programa ou modelo não humano que demonstra uma ampla gama de resolução de problemas e criatividade.</p>
<h2 class="wp-block-heading" id="agent">Agente de IA</h2>
<p class="wp-block-paragraph">Um <strong>agente de IA (Inteligência Artificial)</strong> é um sistema que <strong>percebe o ambiente, toma decisões e age automaticamente para atingir um objetivo</strong> — muitas vezes sem precisar de intervenção humana constante.</p>
<h6 class="wp-block-heading">📌 Em termos simples:</h6>
<blockquote class="wp-block-quote is-layout-flow wp-block-quote-is-layout-flow">
<p class="wp-block-paragraph">É como um “assistente inteligente” que não só responde, mas também <strong>age por conta própria</strong>.</p>
<p class="wp-block-paragraph"></p>
</blockquote>
<h3 class="wp-block-heading">🧠 Como um agente de IA funciona</h3>
<p class="wp-block-paragraph">Um agente de IA normalmente tem três partes principais:</p>
<ol class="wp-block-list">
<li><strong>Percepção</strong> 👀<br>Coleta informações (ex: texto, voz, dados de sistemas)</li>
<li><strong>Raciocínio/Decisão</strong> 🧠<br>Analisa os dados e decide o que fazer</li>
<li><strong>Ação</strong> ⚙️<br>Executa tarefas (responder, enviar algo, chamar uma API, etc.)</li>
</ol>
<h2 class="wp-block-heading">🤖 Exemplos práticos</h2>
<ul class="wp-block-list">
<li><strong>Chatbots avançados</strong> (como assistentes virtuais)<br>→ Respondem perguntas e resolvem problemas</li>
<li><strong>Agentes em e-commerce (agentic retail)</strong><br>→ Recomendam produtos, negociam preços, finalizam compras</li>
<li><strong>Assistentes de produtividade</strong><br>→ Organizem calendário, enviem e-mails, gerenciem tarefas</li>
<li><strong>Sistemas autônomos</strong><br>→ Robôs, carros autônomos</li>
</ul>
<h2 class="wp-block-heading">🔥 Diferença: IA comum vs agente de IA</h2>
<ul class="wp-block-list">
<li><strong>IA comum:</strong> responde quando você pede</li>
<li><strong>Agente de IA:</strong> pode <strong>decidir e agir sozinho</strong>, com autonomia</li>
</ul>
<p class="wp-block-paragraph"></p>
<p class="wp-block-paragraph"></p>
<h4 class="wp-block-heading">🧩 Exemplo no seu contexto (<a href="https://labdx.org/Arquivos/agentic-retail/index.html" type="link" id="https://labdx.org/Arquivos/agentic-retail/index.html">AgentShop</a> / e-commerce)</h4>
<p class="wp-block-paragraph">Um agente de IA poderia:</p>
<ul class="wp-block-list">
<li>Conversar com o cliente</li>
<li>Entender o que ele quer</li>
<li>Buscar produtos automaticamente</li>
<li>Sugerir opções</li>
<li>Aplicar cupons</li>
<li>Finalizar a compra via Stripe</li>
</ul>
<p class="wp-block-paragraph">👉 Ou seja: ele vira um <strong>“vendedor inteligente automatizado”</strong>.</p>
<p class="wp-block-paragraph">Espaçador</p>
<p class="wp-block-paragraph">Separador</p>
<h2 class="wp-block-heading" id="agentic">Agêntico / agêntica</h2>
<p class="wp-block-paragraph">A forma adjetiva de <a href="https://developers.google.com/machine-learning/glossary/?hl=pt-br#agent"><strong>agente</strong></a>. Agêntico se refere às qualidades que os agentes têm (como autonomia).</p>
<h3 class="wp-block-heading" id="agentic-loop">loop agêntico</h3>
<p class="wp-block-paragraph">Um ciclo que um agente percorre até que uma <a href="https://developers.google.com/machine-learning/glossary/?hl=pt-br#termination_condition"><strong>condição de encerramento</strong></a> seja atendida. O ciclo normalmente consiste nas quatro etapas a seguir:</p>
<ol class="wp-block-list">
<li><a href="https://developers.google.com/machine-learning/glossary/?hl=pt-br#observe"><strong>Observe</strong></a></li>
<li><a href="https://developers.google.com/machine-learning/glossary/?hl=pt-br#reason"><strong>Motivo</strong></a></li>
<li><a href="https://developers.google.com/machine-learning/glossary/?hl=pt-br#act"><strong>Agir</strong></a></li>
<li><a href="https://developers.google.com/machine-learning/glossary/?hl=pt-br#feedback"><strong>Feedback</strong></a></li>
</ol>
<h2 class="wp-block-heading" id="agentic-workflow">Fluxo de trabalho com agentes</h2>
<p class="wp-block-paragraph">Um processo dinâmico em que um <a href="https://developers.google.com/machine-learning/glossary/?hl=pt-br#agent"><strong>agente</strong></a> planeja e executa ações de <strong>forma autônoma </strong>para alcançar uma meta. O processo pode envolver raciocínio, invocação de ferramentas externas e autocorreção do plano.</p>
<h2 class="wp-block-heading" id="agent-orchestration">Orquestração de agentes</h2>
<p class="wp-block-paragraph">O gerenciamento e o roteamento centralizados de tarefas em vários <a href="https://developers.google.com/machine-learning/glossary/?hl=pt-br#sub-agent"><strong>subagentes</strong></a> ou chamadas de LLM. A orquestração de agentes divide tarefas complexas em subtarefas menores e as atribui aos subagentes mais eficientes.</p>
<h2 class="wp-block-heading" id="agglomerative-clustering">comando do menos para o mais</h2>
<p class="wp-block-paragraph">Uma forma de <a href="https://developers.google.com/machine-learning/glossary/?hl=pt-br#prompt-chaining"><strong>encadeamento de comandos</strong></a> que divide problemas complexos em um conjunto ordenado de problemas mais simples. Por exemplo, confira uma estratégia de solicitação do menos para o mais para um determinado problema:</p>
<ol class="wp-block-list">
<li>Divida um problema complexo em uma lista ordenada de subproblemas mais simples. Neste exemplo, vamos supor que sejam três subproblemas.</li>
<li>Comando 1: peça ao LLM para resolver o primeiro subproblema. O LLM retorna a resposta 1.</li>
<li>Comando 2: integre toda ou parte da resposta 1 ao comando para resolver o segundo subproblema. O LLM retorna a resposta 2.</li>
<li>Comando 3: integre toda ou parte da resposta 2 ao comando para resolver o terceiro subproblema. A resposta do LLM ao comando 3 é a resposta “final” ao problema complexo inicial.</li>
</ol>
<p class="wp-block-paragraph">Cada etapa depende da solução da etapa anterior.</p>
<p class="wp-block-paragraph">Contraste com o <a href="https://developers.google.com/machine-learning/glossary/?hl=pt-br#tree-of-thought-prompting"><strong>comando de árvore de pensamento</strong></a>.</p>
<h2 class="wp-block-heading" id="tree-of-thought-prompting-tot">Comandos de árvore de pensamento (ToT)</h2>
<p class="wp-block-paragraph">Uma estratégia de comando sofisticada que incentiva um LLM a buscar e refinar as soluções intermediárias mais promissoras e abandonar o restante. O comando de árvore de pensamento usa um algoritmo como este:</p>
<ol class="wp-block-list">
<li>Divida um problema complexo em diferentes ramificações (estratégias em potencial), cada uma composta de várias etapas.</li>
<li>Peça para o LLM trabalhar em cada ramificação de forma independente.</li>
<li>Peça ao LLM para avaliar a qualidade da solução de cada ramificação após cada etapa.</li>
<li>Continue refinando as ramificações mais promissoras e abandone o restante.</li>
<li>Se uma ramificação promissora falhar, volte atrás e tente outras etapas promissoras.</li>
</ol>
<p class="wp-block-paragraph">Solte arquivos aqui para enviar</p>
<p class="wp-block-paragraph">Solte arquivos aqui para enviar</p>
<h2 class="wp-block-heading" id="unlabeled-example">Exemplo não-rotulado</h2>
<p class="wp-block-paragraph"><strong>#fundamentals</strong></p>
<p class="wp-block-paragraph">Um exemplo que contém <a href="https://developers.google.com/machine-learning/glossary/?hl=pt-br#feature"><strong>atributos</strong></a>, mas nenhum <a href="https://developers.google.com/machine-learning/glossary/?hl=pt-br#label"><strong>rótulo</strong></a>. Por exemplo, a tabela a seguir mostra três exemplos não rotulados de um modelo de avaliação de imóveis, cada um com três recursos, mas sem valor da casa:</p>
<figure class="wp-block-table"><table class="has-fixed-layout"><tbody><tr><th class="has-text-align-left" data-align="left">Número de quartos</th><th class="has-text-align-left" data-align="left">Número de banheiros</th><th class="has-text-align-left" data-align="left">Idade da casa</th></tr><tr><td class="has-text-align-left" data-align="left">3</td><td class="has-text-align-left" data-align="left">2</td><td class="has-text-align-left" data-align="left">15</td></tr><tr><td class="has-text-align-left" data-align="left">2</td><td class="has-text-align-left" data-align="left">1</td><td class="has-text-align-left" data-align="left">72</td></tr><tr><td class="has-text-align-left" data-align="left">4</td><td class="has-text-align-left" data-align="left">2</td><td class="has-text-align-left" data-align="left">34</td></tr></tbody></table></figure>
<p class="wp-block-paragraph">No <a href="https://developers.google.com/machine-learning/glossary/?hl=pt-br#supervised_machine_learning"><strong>machine learning supervisionado</strong></a>, os modelos são treinados com exemplos rotulados e fazem previsões com <a href="https://developers.google.com/machine-learning/glossary/?hl=pt-br#unlabeled_example"><strong>exemplos sem rótulo</strong></a>.</p>
<p class="wp-block-paragraph">No aprendizado <a href="https://developers.google.com/machine-learning/glossary/?hl=pt-br#semi-supervised_learning"><strong>semi-supervisionado</strong></a> e <a href="https://developers.google.com/machine-learning/glossary/?hl=pt-br#unsupervised_machine_learning"><strong>não supervisionado</strong></a>, exemplos sem rótulo são usados durante o treinamento.</p>
<p class="wp-block-paragraph">Contraste um exemplo não-rotulado com um <a href="https://developers.google.com/machine-learning/glossary/?hl=pt-br#labeled_example"><strong>exemplo rotulado</strong></a>.</p>
<h2 class="wp-block-heading" id="labeled-example">Exemplo rotulado</h2>
<p class="wp-block-paragraph">Um exemplo que contém um ou mais <a href="https://developers.google.com/machine-learning/glossary/?hl=pt-br#feature"><strong>atributos</strong></a> e um <a href="https://developers.google.com/machine-learning/glossary/?hl=pt-br#label"><strong>rótulo</strong></a>. Por exemplo, a tabela a seguir mostra três exemplos rotulados de um modelo de avaliação de imóveis, cada um com três recursos e um rótulo:</p>
<figure class="wp-block-table"><table class="has-fixed-layout"><tbody><tr><th class="has-text-align-left" data-align="left">Quartos</th><th class="has-text-align-left" data-align="left">Banheiros</th><th class="has-text-align-left" data-align="left">Idade da casa</th><th class="has-text-align-left" data-align="left">Preço da casa (rótulo)</th></tr><tr><td class="has-text-align-left" data-align="left">3</td><td class="has-text-align-left" data-align="left">2</td><td class="has-text-align-left" data-align="left">15</td><td class="has-text-align-left" data-align="left">US$ 345.000</td></tr><tr><td class="has-text-align-left" data-align="left">2</td><td class="has-text-align-left" data-align="left">1</td><td class="has-text-align-left" data-align="left">72</td><td class="has-text-align-left" data-align="left">US$ 179.000</td></tr><tr><td class="has-text-align-left" data-align="left">4</td><td class="has-text-align-left" data-align="left">2</td><td class="has-text-align-left" data-align="left">34</td><td class="has-text-align-left" data-align="left">US$ 392.000</td></tr></tbody></table></figure>
<p class="wp-block-paragraph">No <a href="https://developers.google.com/machine-learning/glossary/?hl=pt-br#supervised_machine_learning"><strong>machine learning supervisionado</strong></a>, os modelos são treinados com exemplos rotulados e fazem previsões com <a href="https://developers.google.com/machine-learning/glossary/?hl=pt-br#unlabeled_example"><strong>exemplos sem rótulo</strong></a>.</p>
<p class="wp-block-paragraph">Contraste exemplos rotulados com exemplos não rotulados.</p>
<p class="wp-block-paragraph">Consulte <a href="https://developers.google.com/machine-learning/intro-to-ml/supervised?hl=pt-br">Aprendizado supervisionado</a> em “Introdução ao machine learning” para mais informações.</p>
<h2 class="wp-block-heading" id="ai-slop">IA slop</h2>
<p class="wp-block-paragraph">#generativeAI</p>
<p class="wp-block-paragraph">Saída de um sistema de <a href="https://developers.google.com/machine-learning/glossary/?hl=pt-br#generative-AI"><strong>IA generativa</strong></a> que prioriza a quantidade em vez da qualidade. Por exemplo, uma página da Web com IA slop é preenchida com conteúdo de baixa qualidade, gerado com IA e produzido de forma barata.</p>
<p class="wp-block-paragraph"></p>
<h2 class="wp-block-heading" id="client-side_ai">IA do lado do cliente</h2>
<p class="wp-block-paragraph">Enquanto a maioria dos recursos de IA na Web depende de servidores, a <em>IA do lado do cliente</em> é executada no navegador do usuário e realiza inferências no dispositivo dele. Isso tem <a href="https://developer.chrome.com/docs/ai/client-side?hl=pt-br">vários benefícios</a>, incluindo menor latência, custo reduzido para criar recursos, maior privacidade do usuário e acesso off-line.</p>
<p class="wp-block-paragraph">A IA do lado do cliente usa modelos menores e otimizados, que são <a href="https://web.dev/articles/client-side-ai-performance?hl=pt-br">otimizados para performance</a>. É possível que esses modelos tenham um desempenho melhor do que modelos maiores do lado do servidor para tarefas específicas. Avalie seu caso de uso para determinar qual solução é ideal para você.</p>
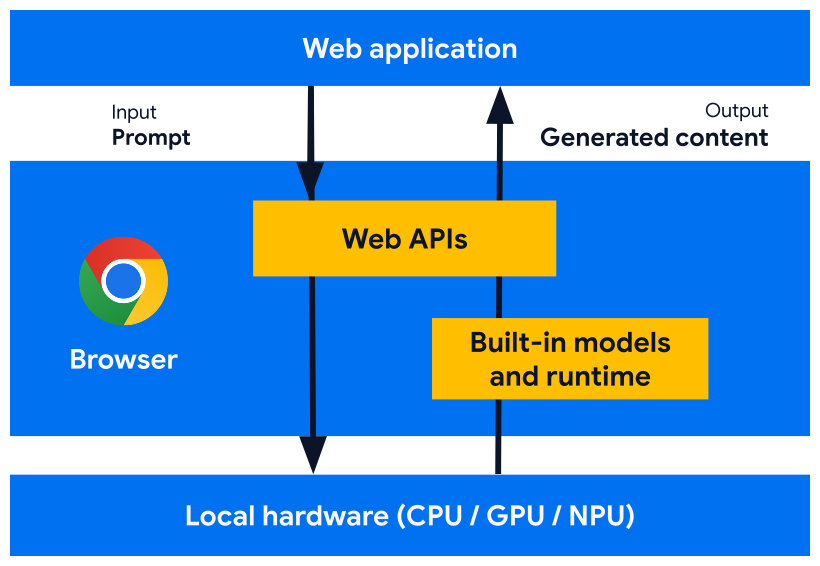
<h3 class="wp-block-heading" id="built-in_ai">IA integrada</h3>
<figure class="wp-block-image"><img src="https://developer.chrome.com/static/docs/ai/glossary/images/built-in-infra.jpg?hl=pt-br" alt=""/><figcaption class="wp-element-caption">Com a IA integrada, seu site se conecta às APIs do navegador ao processador local. O modelo integrado do navegador envia uma resposta, que a API retorna ao seu site.</figcaption></figure>
<p class="wp-block-paragraph">A <a href="https://developer.chrome.com/docs/ai/built-in?hl=pt-br"><em>IA integrada</em></a> é uma forma de IA do lado do cliente, em que os modelos menores são integrados ao navegador. No Chrome, isso inclui o Gemini Nano e modelos especializados. Depois que esses modelos são baixados, todos os sites e aplicativos da Web que usam IA integrada podem pular o tempo de download e ir direto para a execução de recursos e a inferência local.</p>
<p class="wp-block-paragraph">As <a href="https://developer.chrome.com/docs/ai/built-in-apis?hl=pt-br">APIs de IA integradas</a> são projetadas para executar inferência no tipo certo de modelo para a tarefa. Por exemplo, a <a href="https://developer.chrome.com/docs/ai/prompt-api?hl=pt-br">API Prompt</a> executa inferência em um modelo de linguagem, enquanto a <a href="https://developer.chrome.com/docs/ai/translator-api?hl=pt-br">API Translator</a> executa inferência em um modelo especialista integrado.</p>
<h2 class="wp-block-heading" id="server-side_ai">IA do lado do servidor</h2>
<p class="wp-block-paragraph">A <em>IA do lado do servidor</em> abrange serviços de IA baseados na nuvem. Imagine o Gemini 1.5 Pro executado em uma nuvem. Esses modelos tendem a ser muito maiores e mais poderosos. Isso é especialmente verdadeiro para os <a href="https://web.dev/articles/llm-sizes?hl=pt-br">modelos de linguagem grandes</a>.</p>
<h2 class="wp-block-heading" id="hybrid_ai">IA híbrida</h2>
<p class="wp-block-paragraph">A <em>IA híbrida</em> se refere a qualquer solução que inclua um componente de cliente e de servidor. Exemplo:</p>
<ul class="wp-block-list">
<li>Modelos do lado do cliente que têm um fallback para modelos do lado do servidor, criados para tarefas que não podem ser concluídas de maneira eficaz no dispositivo.
<ul class="wp-block-list">
<li>Talvez não haja recursos suficientes no dispositivo.</li>
<li>O modelo ou a API está disponível apenas em determinados ambientes.</li>
</ul>
</li>
<li>Uma divisão de modelo entre cliente e servidor para segurança.
<ul class="wp-block-list">
<li>Por exemplo, é possível dividir um modelo para que 75% da execução aconteça no cliente e os 25% restantes sejam realizados em um servidor. Isso traz <a href="https://developer.chrome.com/docs/ai/client-side?hl=pt-br">benefícios do lado do cliente</a>, permitindo que parte do modelo fique fora do dispositivo, mantendo a privacidade.</li>
</ul>
</li>
</ul>
<p class="wp-block-paragraph">Se você usa a <a href="https://developer.chrome.com/docs/ai/prompt-api?hl=pt-br">API de solicitação</a>, é possível configurar uma arquitetura híbrida com o <a href="https://developer.chrome.com/docs/ai/firebase-ai-logic?hl=pt-br">Firebase AI Logic</a>.</p>
<h2 class="wp-block-heading" id="generative_ai">IA generativa</h2>
<p class="wp-block-paragraph">A <em>IA generativa</em> é uma forma de machine learning que ajuda os usuários a criar conteúdo que parece familiar e imita a criação humana. A IA generativa usa modelos de linguagem para organizar dados e criar ou modificar texto, imagens, vídeo e áudio com base no contexto fornecido. A IA generativa vai além da correspondência de padrões e das previsões.</p>
<p class="wp-block-paragraph">Um <em>modelo de linguagem grande (LLM)</em> tem vários (até bilhões) parâmetros que você pode usar para realizar uma ampla variedade de tarefas, como gerar, classificar ou resumir texto ou imagens.</p>
<p class="wp-block-paragraph">Um <em>modelo de linguagem pequeno (SLM)</em> tem muito menos parâmetros para realizar tarefas semelhantes e pode ser usado no lado do cliente.</p>
<h3 class="wp-block-heading" id="nlp">Processamento de linguagem natural (PLN)</h3>
<p class="wp-block-paragraph">O processamento de linguagem natural é uma classe de ML que ajuda os computadores a entender a linguagem humana, desde as regras de qualquer idioma específico até as idiossincrasias, o dialeto e a gíria usados pelas pessoas.</p>
<p class="wp-block-paragraph">Advanced Heading</p>
<h2 class="wp-block-heading" id="agent"></h2>
<h2 class="wp-block-heading" id="input_and_output">Entrada e saída</h2>
<p class="wp-block-paragraph">Um chatbot não é inerentemente um agente. Enquanto um chatbot responde a um mensageiro (humano ou não) e depende de um modelo para gerar conteúdo, como respostas a perguntas, um agente interage com ferramentas ou um banco de dados para concluir uma tarefa.</p>
<p class="wp-block-paragraph">A entrada e a saída do modelo podem estar em diferentes modalidades, incluindo texto, imagem, áudio e vídeo. Um modelo pode aceitar apenas uma modalidade ou várias (<em>modelos multimodais</em>). É importante confirmar quais modalidades você precisa antes de escolher o modelo.</p>
<p class="wp-block-paragraph">A entrada e a saída podem ser enviadas e recebidas em partes de streaming ou com base em solicitações.</p>
<h3 class="wp-block-heading" id="streaming">Streaming</h3>
<p class="wp-block-paragraph">O <a href="https://developer.chrome.com/docs/ai/streaming?hl=pt-br"><em>streaming</em></a> divide um recurso enviado ou recebido em partes menores, oferecendo resultados em tempo real. A saída é ajustada continuamente à medida que a entrada é adicionada e ajustada.</p>
<p class="wp-block-paragraph">Essa é uma técnica comum para navegadores usarem no recebimento de recursos de mídia, como buffer de vídeo ou carregamento parcial de imagens.</p>
<h3 class="wp-block-heading" id="request-based_output">Saída baseada em solicitações</h3>
<p class="wp-block-paragraph">Para saída baseada em solicitação (ou “sem streaming”), o modelo aguarda a geração de toda a entrada, processa essa entrada como um todo e produz a saída.</p>
<p class="wp-block-paragraph">Por exemplo, em uma janela de chat, em vez de o modal criar uma resposta enquanto o usuário digita, o modelo espera até que o usuário clique em um botão de envio. Depois que a mensagem é enviada, o modelo considera todas as entradas e responde.</p>
<h2 class="wp-block-heading" id="additional_resources"></h2>
Inteligência artificial (IA)
A inteligência artificial (IA) abrange muitas tecnologias complexas e emergentes que antes exigiam intervenção humana e agora podem ser realizadas por um computador.
De modo geral, a IA é um programa ou modelo não humano que demonstra uma ampla gama de resolução de problemas e criatividade.
Agente de IA
Um agente de IA (Inteligência Artificial) é um sistema que percebe o ambiente, toma decisões e age automaticamente para atingir um objetivo — muitas vezes sem precisar de intervenção humana constante.
📌 Em termos simples:
É como um “assistente inteligente” que não só responde, mas também age por conta própria.
🧠 Como um agente de IA funciona
Um agente de IA normalmente tem três partes principais:
Percepção 👀 Coleta informações (ex: texto, voz, dados de sistemas)
Raciocínio/Decisão 🧠 Analisa os dados e decide o que fazer
Um processo dinâmico em que um agente planeja e executa ações de forma autônoma para alcançar uma meta. O processo pode envolver raciocínio, invocação de ferramentas externas e autocorreção do plano.
Orquestração de agentes
O gerenciamento e o roteamento centralizados de tarefas em vários subagentes ou chamadas de LLM. A orquestração de agentes divide tarefas complexas em subtarefas menores e as atribui aos subagentes mais eficientes.
comando do menos para o mais
Uma forma de encadeamento de comandos que divide problemas complexos em um conjunto ordenado de problemas mais simples. Por exemplo, confira uma estratégia de solicitação do menos para o mais para um determinado problema:
Divida um problema complexo em uma lista ordenada de subproblemas mais simples. Neste exemplo, vamos supor que sejam três subproblemas.
Comando 1: peça ao LLM para resolver o primeiro subproblema. O LLM retorna a resposta 1.
Comando 2: integre toda ou parte da resposta 1 ao comando para resolver o segundo subproblema. O LLM retorna a resposta 2.
Comando 3: integre toda ou parte da resposta 2 ao comando para resolver o terceiro subproblema. A resposta do LLM ao comando 3 é a resposta “final” ao problema complexo inicial.
Uma estratégia de comando sofisticada que incentiva um LLM a buscar e refinar as soluções intermediárias mais promissoras e abandonar o restante. O comando de árvore de pensamento usa um algoritmo como este:
Divida um problema complexo em diferentes ramificações (estratégias em potencial), cada uma composta de várias etapas.
Peça para o LLM trabalhar em cada ramificação de forma independente.
Peça ao LLM para avaliar a qualidade da solução de cada ramificação após cada etapa.
Continue refinando as ramificações mais promissoras e abandone o restante.
Se uma ramificação promissora falhar, volte atrás e tente outras etapas promissoras.
Solte arquivos aqui para enviar
Solte arquivos aqui para enviar
Exemplo não-rotulado
#fundamentals
Um exemplo que contém atributos, mas nenhum rótulo. Por exemplo, a tabela a seguir mostra três exemplos não rotulados de um modelo de avaliação de imóveis, cada um com três recursos, mas sem valor da casa:
Um exemplo que contém um ou mais atributos e um rótulo. Por exemplo, a tabela a seguir mostra três exemplos rotulados de um modelo de avaliação de imóveis, cada um com três recursos e um rótulo:
Saída de um sistema de IA generativa que prioriza a quantidade em vez da qualidade. Por exemplo, uma página da Web com IA slop é preenchida com conteúdo de baixa qualidade, gerado com IA e produzido de forma barata.
IA do lado do cliente
Enquanto a maioria dos recursos de IA na Web depende de servidores, a IA do lado do cliente é executada no navegador do usuário e realiza inferências no dispositivo dele. Isso tem vários benefícios, incluindo menor latência, custo reduzido para criar recursos, maior privacidade do usuário e acesso off-line.
A IA do lado do cliente usa modelos menores e otimizados, que são otimizados para performance. É possível que esses modelos tenham um desempenho melhor do que modelos maiores do lado do servidor para tarefas específicas. Avalie seu caso de uso para determinar qual solução é ideal para você.
IA integrada
Com a IA integrada, seu site se conecta às APIs do navegador ao processador local. O modelo integrado do navegador envia uma resposta, que a API retorna ao seu site.
A IA integrada é uma forma de IA do lado do cliente, em que os modelos menores são integrados ao navegador. No Chrome, isso inclui o Gemini Nano e modelos especializados. Depois que esses modelos são baixados, todos os sites e aplicativos da Web que usam IA integrada podem pular o tempo de download e ir direto para a execução de recursos e a inferência local.
As APIs de IA integradas são projetadas para executar inferência no tipo certo de modelo para a tarefa. Por exemplo, a API Prompt executa inferência em um modelo de linguagem, enquanto a API Translator executa inferência em um modelo especialista integrado.
IA do lado do servidor
A IA do lado do servidor abrange serviços de IA baseados na nuvem. Imagine o Gemini 1.5 Pro executado em uma nuvem. Esses modelos tendem a ser muito maiores e mais poderosos. Isso é especialmente verdadeiro para os modelos de linguagem grandes.
IA híbrida
A IA híbrida se refere a qualquer solução que inclua um componente de cliente e de servidor. Exemplo:
Modelos do lado do cliente que têm um fallback para modelos do lado do servidor, criados para tarefas que não podem ser concluídas de maneira eficaz no dispositivo.
Talvez não haja recursos suficientes no dispositivo.
O modelo ou a API está disponível apenas em determinados ambientes.
Uma divisão de modelo entre cliente e servidor para segurança.
Por exemplo, é possível dividir um modelo para que 75% da execução aconteça no cliente e os 25% restantes sejam realizados em um servidor. Isso traz benefícios do lado do cliente, permitindo que parte do modelo fique fora do dispositivo, mantendo a privacidade.
A IA generativa é uma forma de machine learning que ajuda os usuários a criar conteúdo que parece familiar e imita a criação humana. A IA generativa usa modelos de linguagem para organizar dados e criar ou modificar texto, imagens, vídeo e áudio com base no contexto fornecido. A IA generativa vai além da correspondência de padrões e das previsões.
Um modelo de linguagem grande (LLM) tem vários (até bilhões) parâmetros que você pode usar para realizar uma ampla variedade de tarefas, como gerar, classificar ou resumir texto ou imagens.
Um modelo de linguagem pequeno (SLM) tem muito menos parâmetros para realizar tarefas semelhantes e pode ser usado no lado do cliente.
Processamento de linguagem natural (PLN)
O processamento de linguagem natural é uma classe de ML que ajuda os computadores a entender a linguagem humana, desde as regras de qualquer idioma específico até as idiossincrasias, o dialeto e a gíria usados pelas pessoas.
Advanced Heading
Entrada e saída
Um chatbot não é inerentemente um agente. Enquanto um chatbot responde a um mensageiro (humano ou não) e depende de um modelo para gerar conteúdo, como respostas a perguntas, um agente interage com ferramentas ou um banco de dados para concluir uma tarefa.
A entrada e a saída do modelo podem estar em diferentes modalidades, incluindo texto, imagem, áudio e vídeo. Um modelo pode aceitar apenas uma modalidade ou várias (modelos multimodais). É importante confirmar quais modalidades você precisa antes de escolher o modelo.
A entrada e a saída podem ser enviadas e recebidas em partes de streaming ou com base em solicitações.
Streaming
O streaming divide um recurso enviado ou recebido em partes menores, oferecendo resultados em tempo real. A saída é ajustada continuamente à medida que a entrada é adicionada e ajustada.
Essa é uma técnica comum para navegadores usarem no recebimento de recursos de mídia, como buffer de vídeo ou carregamento parcial de imagens.
Saída baseada em solicitações
Para saída baseada em solicitação (ou “sem streaming”), o modelo aguarda a geração de toda a entrada, processa essa entrada como um todo e produz a saída.
Por exemplo, em uma janela de chat, em vez de o modal criar uma resposta enquanto o usuário digita, o modelo espera até que o usuário clique em um botão de envio. Depois que a mensagem é enviada, o modelo considera todas as entradas e responde.

Deixe um comentário